

咨询热线
400-123-4567传真:+86-123-4567
ML优化器Sophia vs Adam 性能验证
怎么快速训练LLM也是LLM快速落地应用中的重要一环,新出的Sophia优化器是近期斯坦福新提出的方案之一。刚好有知友 @Michael在问这个新的Sophia优化器效果怎么样,我也想验证下效果和可借鉴的点,特此记录分享一下。
从下图通过直观感受,能看到Sophia优化器比我们常用的Adam需要更少的步数从 。论文结论是训练同一个nanoGPT模型,使用优化器Sophia比Adam速度快2倍。

git clone https://github.com/Liuhong99/Sophia.git
conda create -n sophia python==3.8
conda activate sophia
pip install torch==2.0 transformers datasets tiktoken wandb -i https://mirror.baidu.com/pypi/simplehttps://huggingface.co/datasets/openwebtext (示例数据) 示例数据蛮大的。
stas/openwebtext-10k · Datasets at Hugging Face (示例数据的弟弟)想快速体验的可先用这个小数据
先下载数据,网络稳定网速好的同学可跳过下载部分,直接运行Sophia/data/openwebtext/prepare.py,会自动下载数据和预处理。
下载大数据链接经常中断的可试下博主土办法, low但管用.
#新建download.py
import time
from datasets import load_dataset # huggingface datasets
while True:
try:
dataset = load_dataset("openwebtext" )
except Exception as e:
time.sleep(2)
print("链接失败...., 重试")
continue
print("good boy. ")
breaks下载完了,再运行预处理脚本: Sophia/data/openwebtext/prepare.py
PS: 可能会遇到路径错误bug, 根据情况修改即可
单卡24G刚好够跑这个小的 123.59M参数。由于数据下载的原因,先跑了一个10k的小数数据。
昨天大数据没下载完,想着用10K的小数据跑下验证下效果。但从10k数据暂时观察不到明显的收益,adam和sophia的收敛速度差不多,差距不明显,应该是数据太少没有拉开明显的差距?。训练结果如下图
# 参数啥也没改,数据换成了10k的数据
# train small GPT2 with sophia
torchrun --standalone --nproc_per_node=1 train_sophiag.py \\
config/train_gpt2_small_sophiag.py --batch_size=8 \\
--gradient_accumulation_steps=6
# train small GPT2 with adam
torchrun --standalone --nproc_per_node=1 train_adam.py \\
config/train_gpt2_small_adam.py --batch_size=8 \\
--gradient_accumulation_steps=6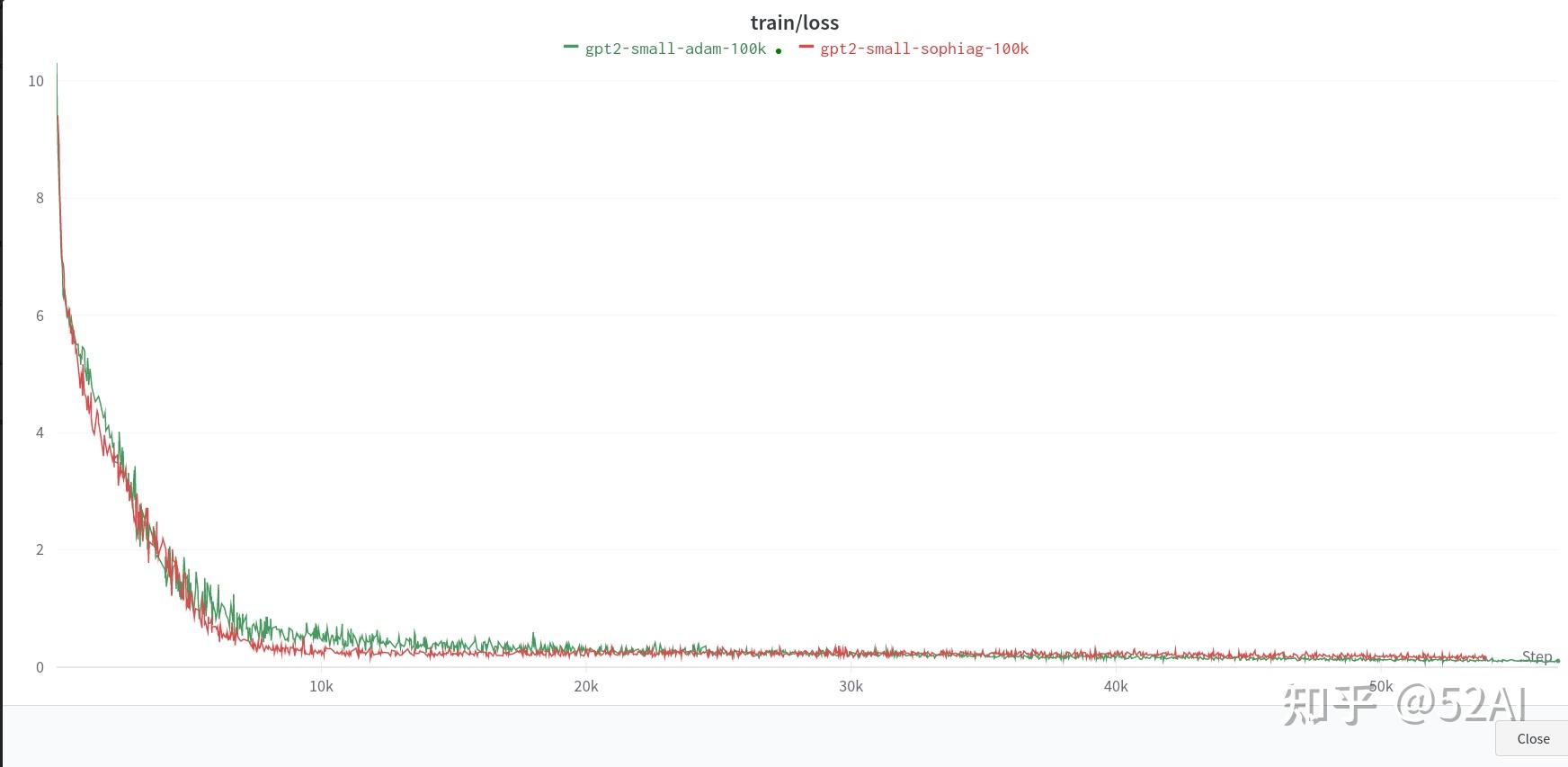
# 参数啥也没改,数据换成了全量的数据
# train small GPT2 with sophia
torchrun --standalone --nproc_per_node=1 train_sophiag.py \\
config/train_gpt2_small_sophiag.py --batch_size=8 \\
--gradient_accumulation_steps=6
# train small GPT2 with adam
torchrun --standalone --nproc_per_node=1 train_adam.py \\
config/train_gpt2_small_adam.py --batch_size=8 \\
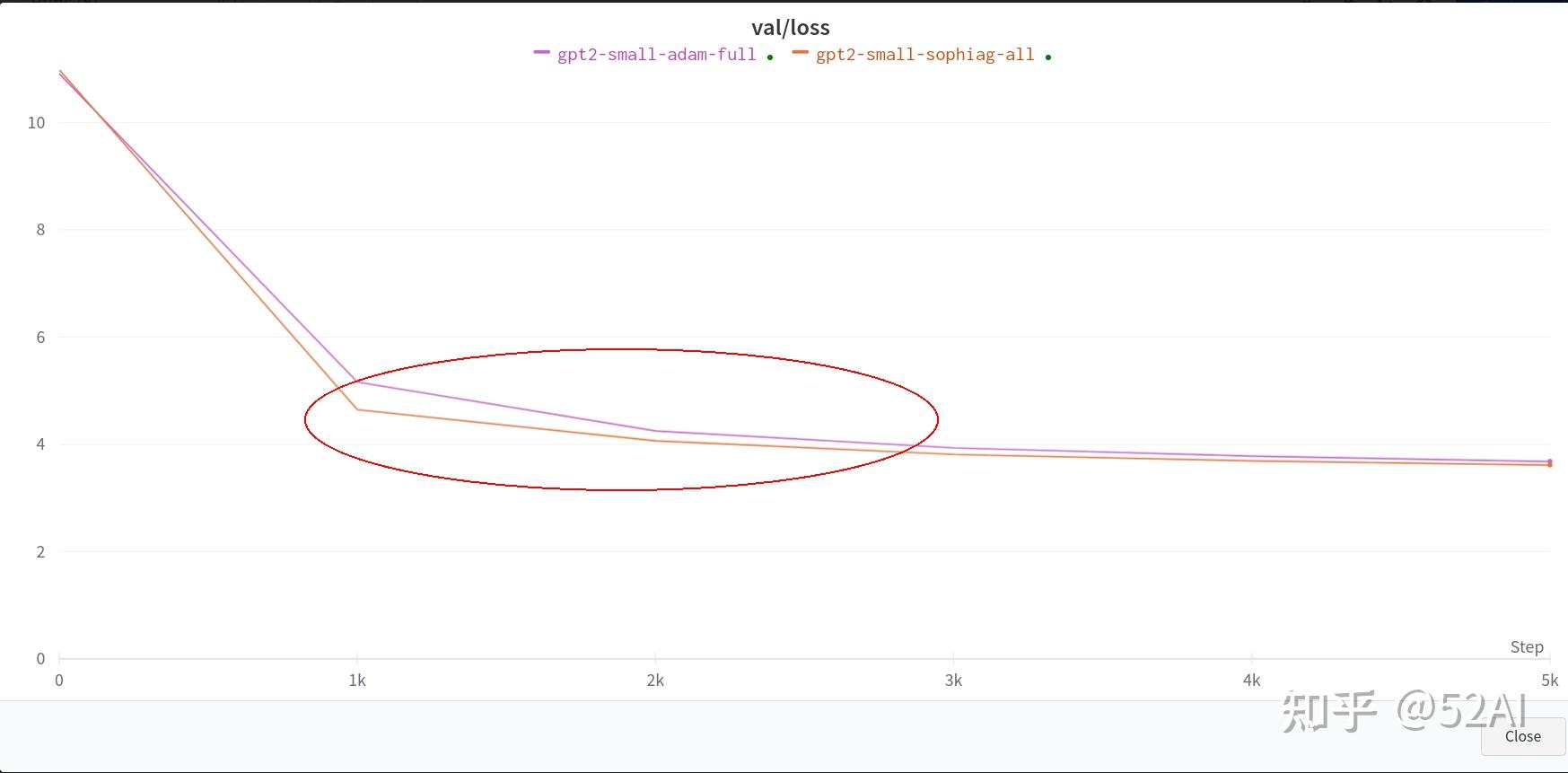
--gradient_accumulation_steps=6全量数据 + 单卡3090 : 无明显收敛速度上的提升。
这里使用作者示例中的全量数据, 和上面训练同一个小参数的模型的结果,默认参数,单卡.
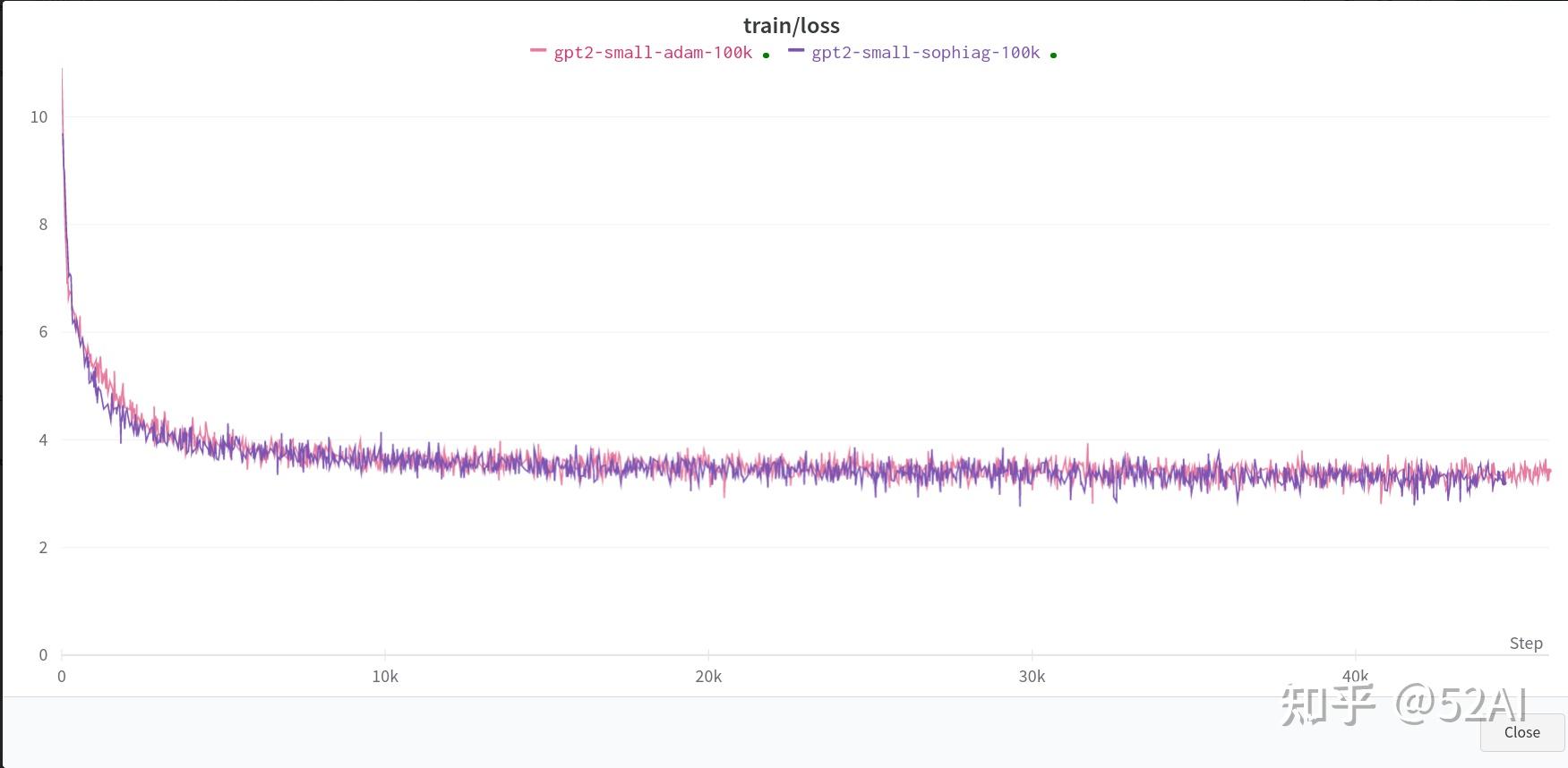
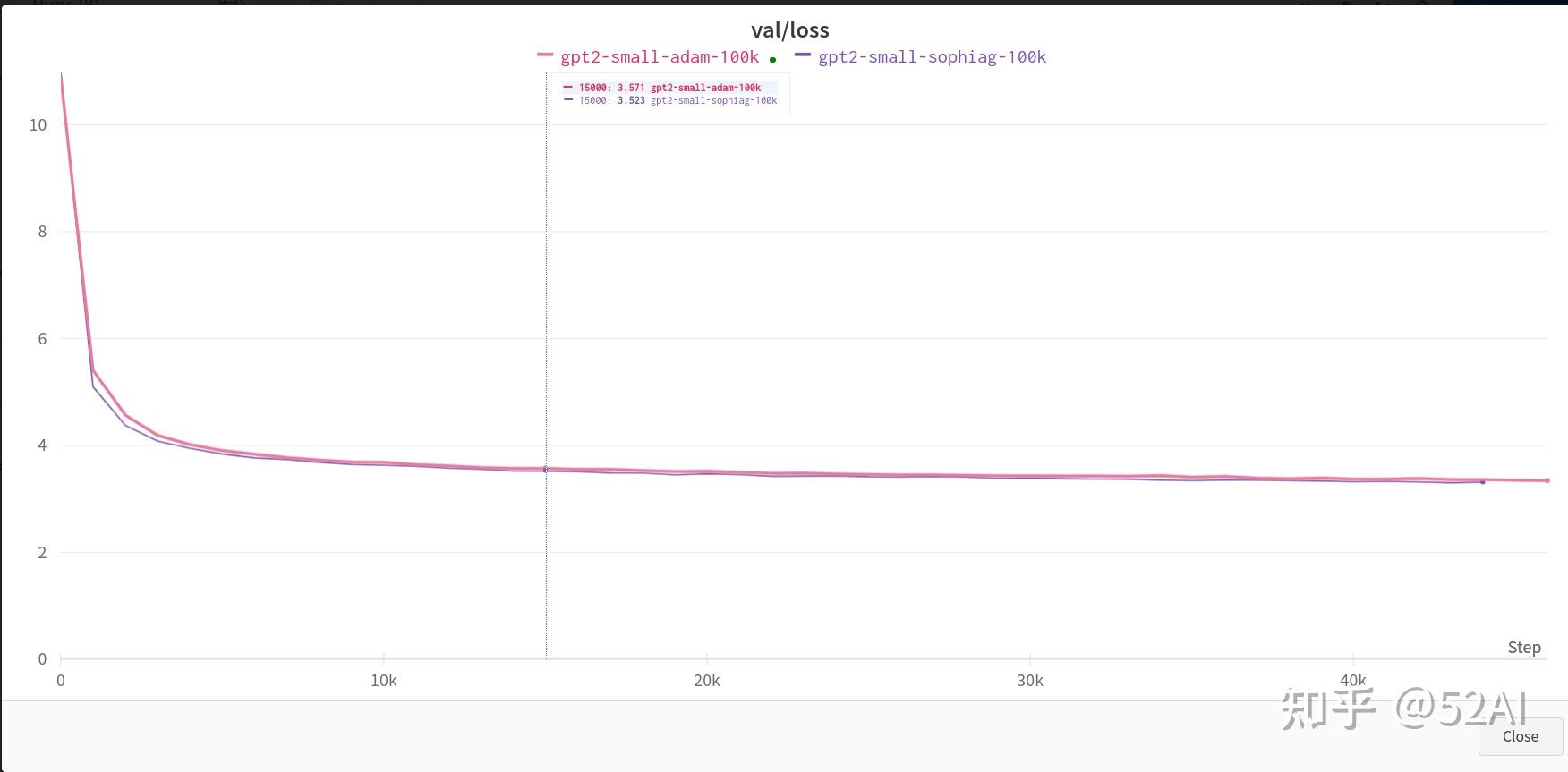
全量数据 + 2x3090测试结果: 能看到一点Sophia比Adam模型收敛更快的效果,但并没到2x的效果.
# 参数啥也没改,数据换成了全量的数据,2 x 3090
# train small GPT2 with sophia
torchrun --standalone --nproc_per_node=2 train_sophiag.py \\
config/train_gpt2_small_sophiag.py --batch_size=8 \\
--gradient_accumulation_steps=6
# train small GPT2 with adam
torchrun --standalone --nproc_per_node=2 train_adam.py \\
config/train_gpt2_small_adam.py --batch_size=8 \\
--gradient_accumulation_steps=6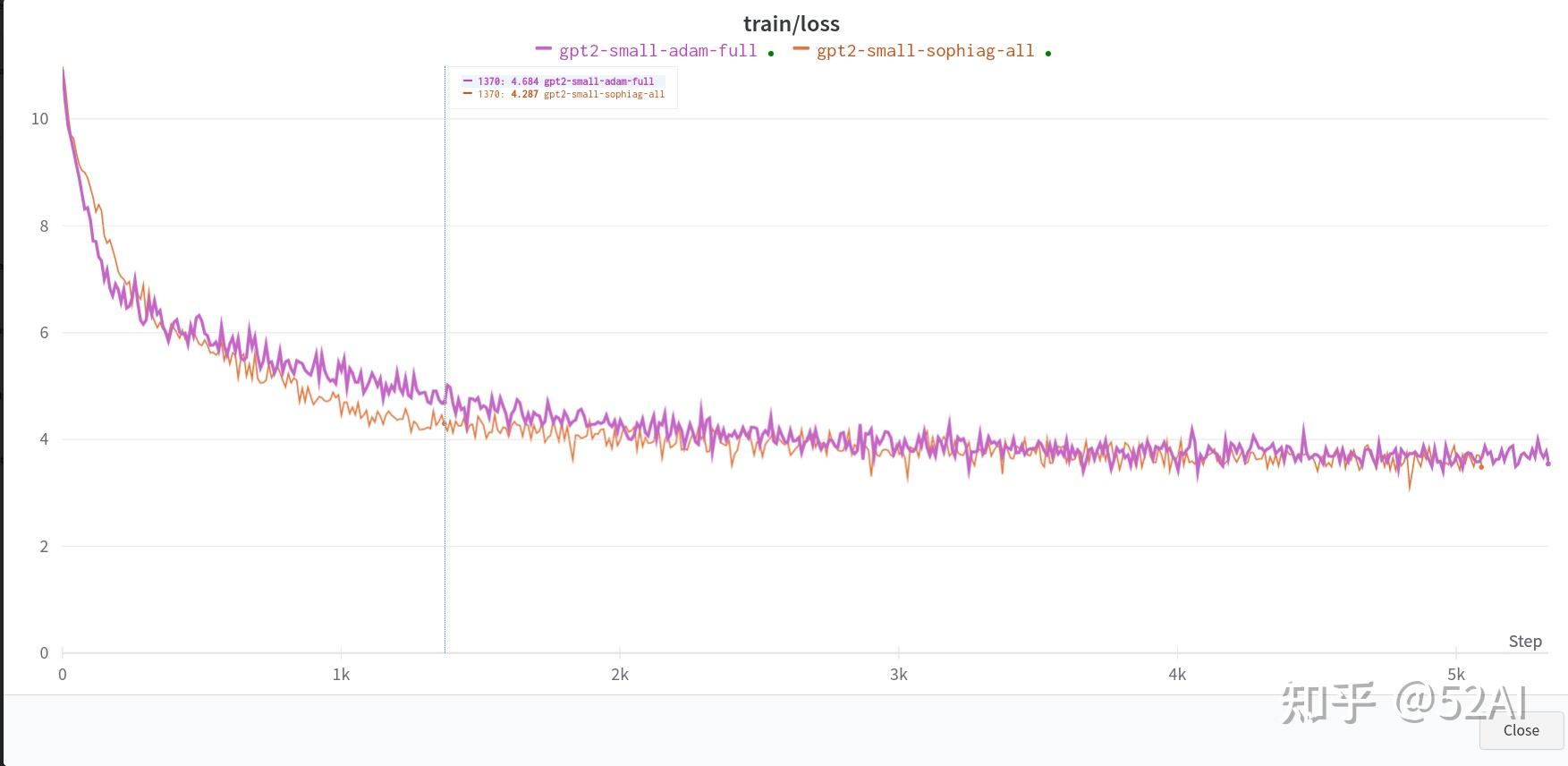
当然示例使用的是10 x 24G跑的,没那么多卡来验证, 可看下作者放出来的小模型对比训练结果,官方示例中Sophia的收敛速度优势体现是比较明显的。
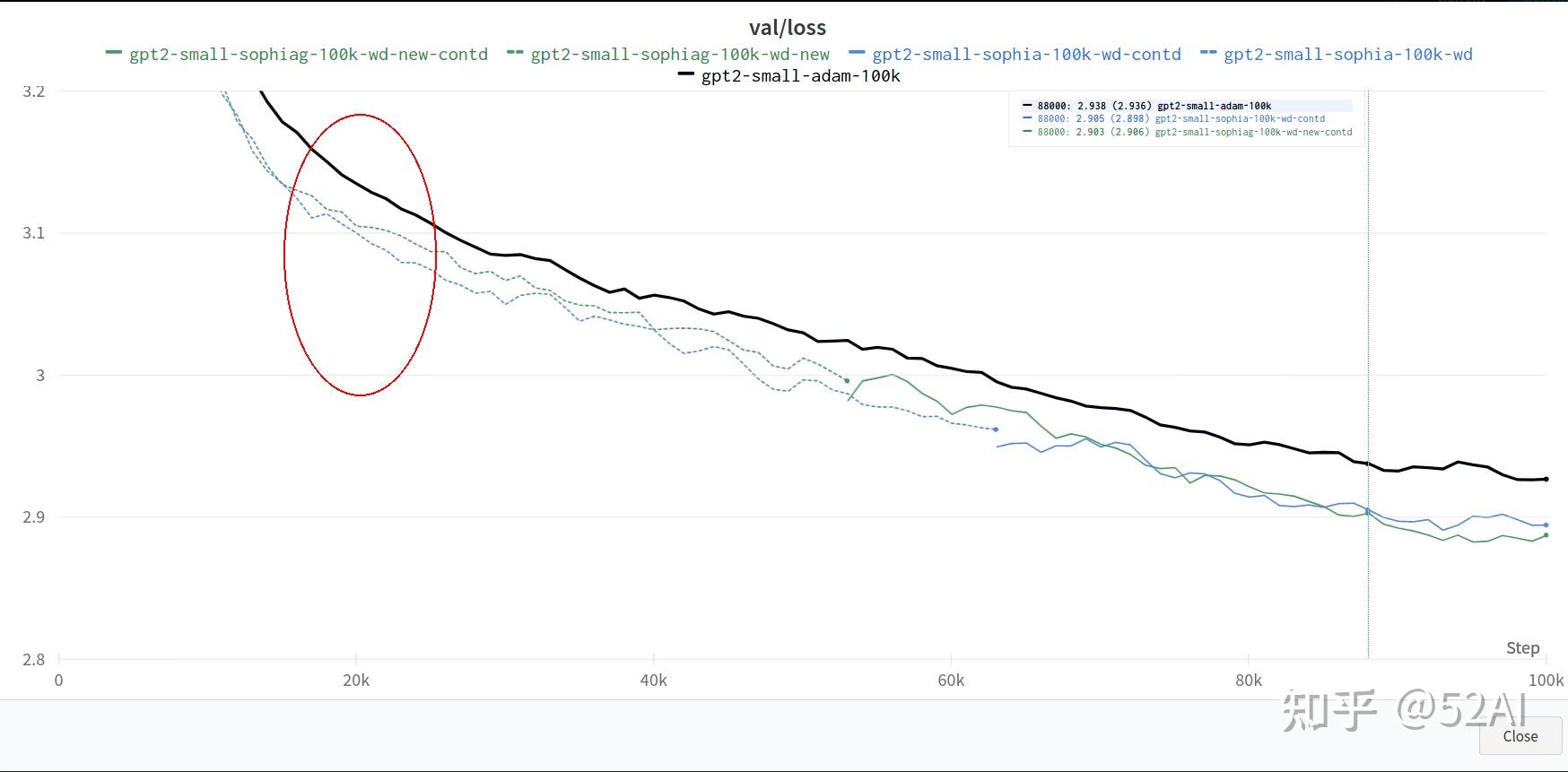
Sophia适用从头训练大模型, 且在batchsize更大的时候训练速度提升效果会更明显,小batchsize参数训练, Adam和Sophia不会有啥明显速度提升效果。因此像做LLM高效微调,可能收益并不会很明显。
参考
code: https://github.com/Liuhong99/Sophia
paper : Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training
————————————————————————
@52AI | 点赞关注不迷路 · 持续关注更新计算机视觉和自然语言处理的前沿技术


