

咨询热线
400-123-4567传真:+86-123-4567
优化器(凸性、梯度、动量、Adagrad、RMSProp及Adam优化)
目录
? ? ? ? 优化器(Optimizer)是机器学习和深度学习中的一个重要组件,用于调整模型参数以最小化(或最大化)损失函数。优化器的主要目标是通过更新模型的参数,使损失函数的值最小化。它是训练模型的关键组成部分,帮助模型逐渐收敛到最佳参数配置,以提高模型的性能。
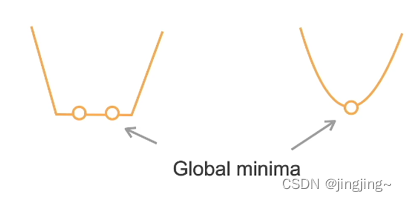
? ? ? ? ?其可主要分为以下三点:局部最小值、鞍点和梯度消失,通过算法的不断优化,可以对上述问题进行缓解(如动量优化器(Momentum)、Adam优化器等)。

? ? ? ? 如上图某函数f(x)图形,local minimun为局部最小,而global minimum才为全局最小,在优化过程中,可以会将局部最小误认为全局最小。
? ? ? ? 鞍点是梯度消失的另一个原因。鞍点(saddle point)是指函数的所有梯度都消失但既不是全局最小值也不是局部最小值的任何位置。考虑这个函数(如下图所示)f(x) = x^3。它的一阶和二阶导数在x = 0时消失。这时优化可能会停止,尽管它不是最小值。

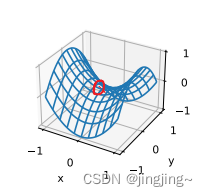
? ? ? ? 另一种函数f(x, y) = x2 -y2。它的鞍点为(0, 0)。这是关于y的最大值,也是关于x的最小值。此外,它看起来像个马鞍,这就是鞍点的名字由来(如下图所示,圈红的为鞍点)。
? ? ? ? ?梯度消失(Gradient Vanishing),特别是在使用深层神经网络(具有多个隐藏层)进行训练时。这个问题通常发生在使用梯度下降或其变种进行反向传播时。在神经网络的梯度逐渐减小到接近零,导致底层神经元的权重几乎不再更新,从而使底层网络层学习到的特征变得不稳定或无效。
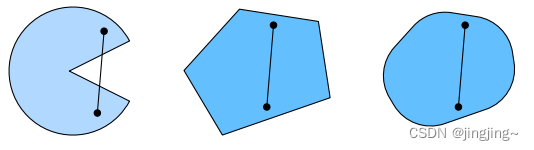
凸集(convex set)是凸性的基础。简单地说,如果对于任何a, b ∈ X,连接a和b的线段也位于X中,则向量空间中的一个集合X是凸(convex)的,如下图所示,左变第一个连线之后,有一部分不在趋于里,即是非凸的,而右边两个图则是凸的。
? 若函数f :C→R是凸当且仅当f(ax +(1 - a)y)≤af(x)+(1 -a)f(y)? ,全部a ∈[0,1] , 全部x,y ∈c。如果x ≠ y,a ∈ (0,1)时不等式严格成立,那么叫严格凸函数,如下图所示。

如果代价函数f是凸的,且限制集合C是凸的,那么就是凸优化问题,那么局部最小一定是全局最小,严格凸优化问题有唯一的全局最小。
上图中左不是严格的凸函数,因此最优点不唯一,右图为严格凸函数,最优点是唯一的。
1、凸
线性回归f(x)= l|Wx一 bl.
Softmax回归
2、非凸:其他
MLP,CNN,RNN, attention, ...,其中如CNN本是线性但上激活函数了。
深度学习模型大多是非凸
1-3节可参考:书籍《动手学深度学习》以及视频:72 优化算法【动手学深度学习v2】_哔哩哔哩_bilibili
梯度下降有三种不同的形式:
批量梯度下降BGD、随机梯度下降SGD、小批量梯度下降MBGD
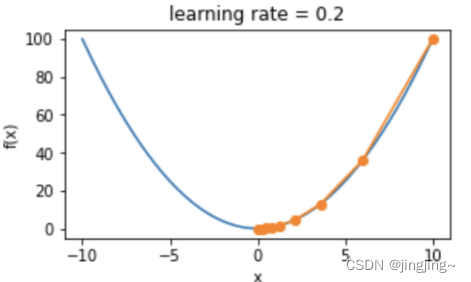
其迭代方法: ,以f(x)=x^2为例,学习率为0.2,其梯度下降如下图所示。
,以f(x)=x^2为例,学习率为0.2,其梯度下降如下图所示。
其迭代方法: ,以f(X)=x1^2?+2x2^2
,以f(X)=x1^2?+2x2^2
为例,学习率为0.4,如下图所示,其中蓝色线为目标函数的等高线,橙色为梯度下降的最优点。

思想:让参数的更新具有惯性, 每一步更新,都是由前面梯度的累积?v?和当前点梯度?g?组合而成。
公式?:
累计梯度更新:v←αv+(1?α)g.其中,α为动量参数,v为累计梯度,v为当前梯度,η为学习率,梯度更新:w←w?η?v
优点:
1、加快收敛能帮助参数在 正确的方向上加速前进
2、他可以帮助跳出局部最小值
Adagrad优化算法被称为自适应学习率优化算法,之前讲的随机梯度下降法,对所有的参数,都是使用相同的、固定的学习率进行优化的,但是不同的参数的梯度差异可能很大,使用相同的学习率,效果不会很好。
Adagrad 思想:对于不同参数,设置不同的学习率。
方法:对于每个参数,初始化一个 累计平方梯度r=0,然后每次将该参数的梯度平方求和累加到这个变量?r?上:![]()
然后,在更新这个参数的时候,学习率就变为:?
权重更新:
其中,g为梯度;r为累积平方梯度(初始为0) ;η为学习率;δ为小参数,避免分母为0,一般取值为10的负10次。
这样,不同的参数由于梯度不同,他们对应的r大小也就不同,所以学习率也就不同,这也就实现了自适应的学习率。
总结: Adagrad 的核心想法就是,如果一个参数的梯度一直都非常大,那么其对应的学习率就变小一点,防止震荡,而一个参数的梯度一直都非常小,那么这个参数的学习率就变大一点,使得其能够更快地更新,这就是Adagrad算法加快深层神经网络的训练速度的核心。
RMSProp:Root Mean Square Propagation 均方根传播
RMSProp 是在 adagrad 的基础上,进一步在学习率的方向上优化
累计平方梯度:?![]()
参数更新:?![]()
其中,g为梯度,r为累积平方梯度(初始为0) ,λ为衰减系数,η为学习率,δ为小参数(避免分母为0)。
在Grandient Descent 的基础上,做了如下几个方面的改进:
1、梯度方面增加了momentum,使用累积梯度:![]()
2、同 RMSProp 优化算法一样, 对学习率进行优化,使用累积平方梯度:?![]()
3、偏差纠正:?![]()
再如上3点改进的基础上,权重更新:?![]()
为什么要进行偏差纠正?
第1次更新时,?![]() ,由于?v0的初始是0,且α值一般会设置为接近于1,因此t较小时,v的值是偏向于0的。
,由于?v0的初始是0,且α值一般会设置为接近于1,因此t较小时,v的值是偏向于0的。
1、深度学习模型大多是非凸
2、小批量随机梯度下降是最常用的优化算法
3、冲量对梯度做平滑
4、Adam对梯度做平滑,且对梯度各个维度值做重产整
?1-3节参考:书籍《动手学深度学习》以及视频:72 优化算法【动手学深度学习v2】_哔哩哔哩_bilibili
4-8可参考博客:优化器 (enzo-miman.github.io)以及up主视频:https://www.bilibili.com/video/BV1jh4y1q7ua/


